说来惭愧我知道scheme并断断续续地学了十年,但从来没有真正用过,甚至理论都没有入门。虽然记录了一堆,但至今没想出scheme在CURD领域有什么用,字符串能力孱弱到只能取子串和拼接,完全无法用于web开发。
lisp族语言与结构化思想
熟悉了vim的sexp模式后,再进行lisp族语言编程,这时操作时脑中思考的就不再是一行文本,而是一整个表达式块,我要在这个表达式外再施加一层操作,又或是去掉这层表达式,而因为表达式的表述如此简洁,在纯文本编辑器中对复杂表达式的引用也能做到十分自然。整个体验完全不同于其它的编程语言。
此处的结构化不是指结构化编程,而是看待代码时,不是单纯的文本,而是一块块结构,编辑、移动、添加和删除的对象,都是以结构的思维去操作。
插件操作记录
i 在光标所在的表达式之外增加一对括号,并把光标置于前面。I则置于后面 w 将光标所在的元素,外包一对括号,光标置于前面,W则置于后面 h 将光标移动到表达式开头,进入插入模式,l则光标到末尾 - (或) 光标向外以表达式为单位移动,可带前缀数字
- [[ 或 ]] 顶层表达式是最高级单元,这个操作解决顶层表达式移动的问题
- [e 或 ]e,同样是移动表达式,且把表达式内容用visual模式引用起来
asdf和quicklisp
asdf类似make,发行版自带,先(require "asdf")再(asdf:asdf-version)查看版本。而quicklisp类似包管理器,要下载文件并用ecl --load quick.lisp进入,再执行命令等待。
HOME/quicklisp/目录下保存了包的内容,按代码和元信息分目录保存。
exit和quit区别
仅在ECL验证过,执行错误语句会进入可恢复区(可以认为是栈深了一层),用quit回到toplevel,而exit不管处在哪一层堆栈,直接退出。
3个处理阶段
看似简单的表达式解析,其实细分为3个阶段
- 读取期read time,将外部文本表示解析为语法对象syntax object,标记出宏,在下一环节处理
- 编译期compile time,此时已全部是syntax object构成的列表形式,进行宏展开。由于没有求值,替换是在语法对象层面
- 运行期run time,将函数和参数按顺序求值,得到最终结果
大部分字符在读取期和编译期的呈现是一样的,但是如表示字符串的双引号,表示数组的#,会导致一段文本变成不同的语法对象,进而影响编译期的处理。或者反过来讲,编译期的对象,可以想象成是struct,有多个维度。而文本表示则只能是平铺的,之所以会混淆,往往是维度单一的语法对象(最常见的就是变量名)。
从文本表示到语法对象的变化,由读取宏来完成(lexer阶段)。quote简写形式单引号,就是典型的读取宏,具备递归能力,比编译期宏更强大。
还有一种compiler macro不是普通的宏,compiler macro是可选的对函数进行优化的提示,CL规范里甚至规定可以忽略compiler macro。
学Scheme经历的误区
从SICP上手的人往往觉得一个list类型包打天下,以致于看到R5RS中特别定义vector都很惊讶。其实就像其它成熟语言一样,容器有很多分类
- Sequence,顺序容器的统称
- List,特点是长度可变,访问耗时O(n)。含aList和pList子型
- Array,特点是长度固定,在CL中支持多维,访问耗时O(1)。含vector和string
- HashMap,无序容器
- Struct,关联数据
car的返回,更倾向于scalar的值,而cdr通常是list。
mapcar遍历Sequence容器,而maphash遍历Hash容器。scheme原版没有hash,所以mapcar被简化为map,但并不代表这样真的对。
绑定let和赋值setq的区别
每个let块会创建新的scope和新的storage place保存值,如果和外层变量同名,以栈的方式实现遮蔽,块结束后弹出从而恢复前一个值。setq复用storage place,实现也简单得多。
从知乎上看到,scheme的意义,觉得写得非常精彩。
在R7RS 88页的篇幅里,塞进了相同尺寸规格的语言无法企及的复杂性。从文法层面的directive, datum label, external representation 与read的联动,到 语义层面的numeric tower, region, proper tail recursion, macro, continuation, environment, evaluation 与eval的联动。Scheme以一种偏执的近乎反实用主义的态度展现了作者的脑洞,回答了这样一个问题:如果有这么一门语言,不用考虑机器实现的便利,不用考虑用户的使用感受,不用考虑设计的可扩展性,尽可能小的篇幅内尽可能多地展现符号操纵的概念,方法,行为和联系。它该是什么样的?
TinyScheme的运行过程
其前身是MiniScheme,代码量不到2500行,大量使用全局变量,风格算不上好,但对于trace来说很方便。
car和cdr是lisp系最典型的特征,通过宏包装后,在C层面大量使用。为了减少分配碎片,一次性先分配连续的内存,其中每个元素典型的tag value风格。每次分配或释放都会将cdr指向正确的位置。
struct cell{
tag;
union : {
struct pair {
cell* left;
cell* right;
};
}
}
虚拟机运行中,共用到4个寄存器。args, envir, code, dump。其中dump值得一说,可以将它等效地认为是C语言的栈。顺便说句cadr的读法是从右往左,先cdr再car,取第2个元素,习惯表示记住就行。
运行前先将args设置为pair,car是待运行的文件名,其它3个寄存器为NULL。
第一条指令是LOAD,接下来是T0LVL,此时会把envir绑定到global env,这个阶段只是准备,所以命名为0。然后会依次向dump保存VALUEPRINT和T1LVL,由于cons队列属性,后保存的先被取出执行,而T1LVL实质就是eval,到这里就已经构成了LOAD(就是READ),EVAL,PRINT的完整过程,加上外层的无限循环,整个REPL就完备了。
因为初始化的时候,往往把常用的放在前面,但保存的数据结构也是cons,导致搜索的耗时会变长,似乎逆序是更好的选择。
有3个在执行中很常用的宏,s_goto,s_save,s_return。goto直接更改op并进入下一次循环,save和return要配合dump寄存器保存所有的状态。s_save将op, args, envir, code,倒序挂在dump前面,s_return会将当前求得的值保存在value(也叫ret_value),然后从dump中以save的逆序取出4个元素,赋值给op, args, envir, code。此后dump就回到上一次状态,类似x86的push esp;push ebp;和pop指令,最终的目的都是要保证栈平衡。return比save多一步赋值value也好理解,因为已经把这次的求值结果保存在value了,接下来就是取下一个op,这时可能会用到value。在OP_DEF1的结尾就是return,之后从dump中取出op,但是如果注释掉了OP_VALUEPRINT语句,堆栈就不平衡,导致下一次eval时op是乱码,引发程序崩溃。
典型如(define a 3)这句,先READ,发现是左括号,进入RDSEXPR,读到ATOM后,先save一个RDLIST,再goto到RDSEXPR,所以看起来会有两次连续的RDSEXPR。每次RDLIST都会从上一步的RDSEXPR得到value,依次是define, a, 3。读完之后,这3个元素就构成一个完整的list,进入EVAL开始求值。
由于只有闭包,函数定义和对象的类型是一样的。car是code,cdr是env。普通的函数env指向global,对象的cddr是global,cdar是其upvalue。code的car是参数列表,cdr是行为,通常是lambda。在闭包合成的过程中,被绑定的参数被挂接到global前面,从而在求值时就可以先找到。
看个示例
(define (bi a)
(lambda () (+ a 3)))
(define c (bi 1))
函数定义bi是这样
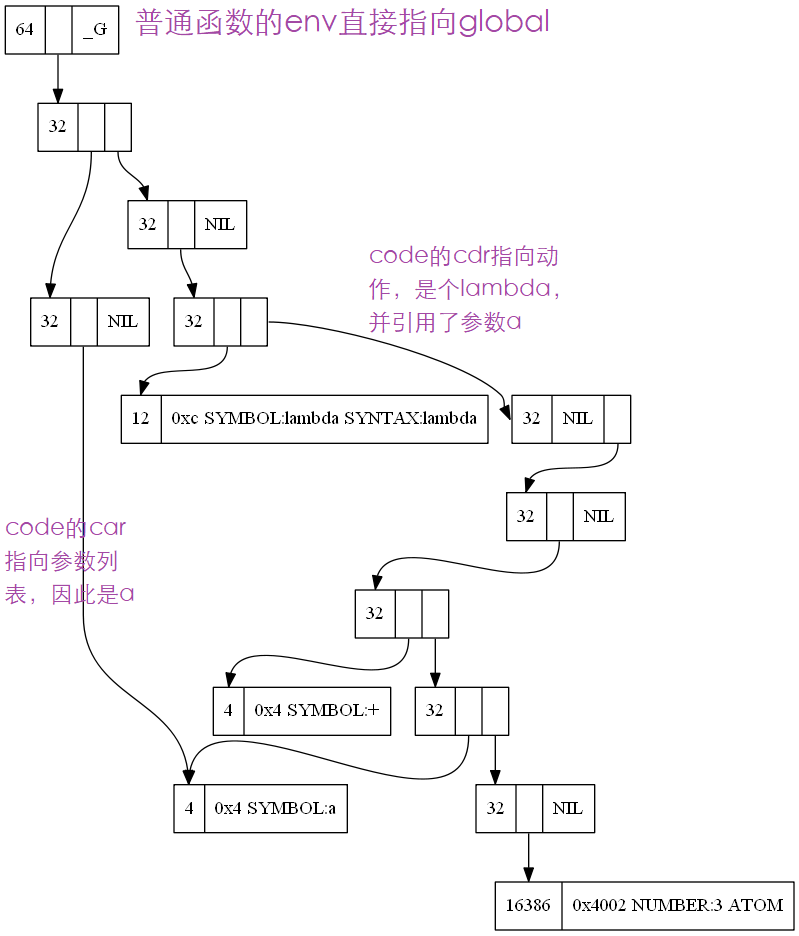
生成的闭包c是这样
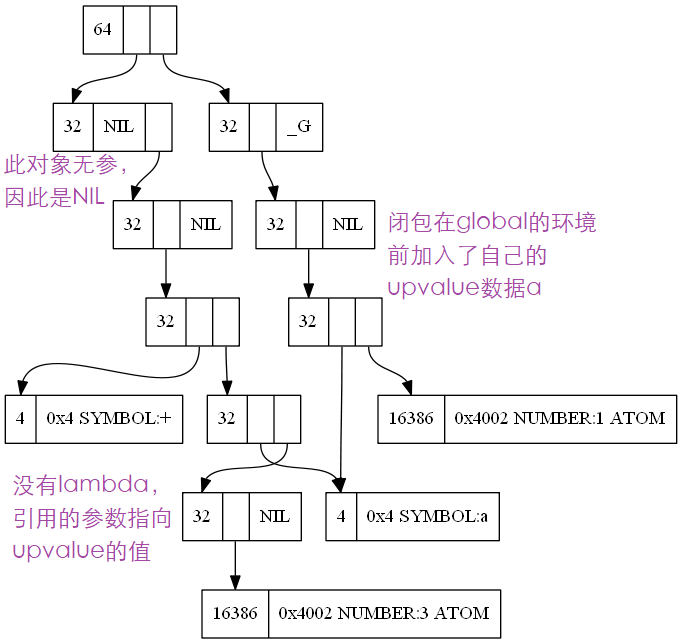
global由于始终按向car上挂接,非常不平衡,是个优化点。
几个实现简探Gambit/Chibi/Chicken/S7
Gambit
两个主要执行程序:gsi和gsc,gsi是执行器,可以debug,gsc将scm源码先编译成一种叫gvm(gambit virtual machine)的中间语言,再翻译成C源码方式。转译后的源码内容是各种宏的排列,大约是gvm语言的转译版,完全没有可读性。
用gsc -c生成的c文件是,没有main函数,无法编译成可执行程序。main函数的定义在libgambit.a里。但是要将main函数和用户实现函数联系起来,还必须有一个称为link文件的东西。要用gsc -link方式生成。如果一份example.scm文件会生成example.c和example_.c两个文件。后一个文件接近500K大小,但是不管scm文件的内容是什么,这个link文件的内容几乎是一样的,因为它的作用主要是初始化scheme环境并调用用户代码。因此有多个scm文件时,只要对其中的主启动文件生成link文件就可以了。
最后再链接入libgambit.a就能生成平台可执行程序了。不过在windows上用gcc编译时提示找不到chkstk_ms函数,chkstk要解决的是这样一个问题:每个程序默认分配4K栈长度(64位是8K),如果超过这个长度,会触发OS的缺页机制,但如果超过2页,可能会引起非法访问,所以微软加了这个函数。GCC也有类似机制,但函数名却不一样。有人说从VC拷贝chkstk.obj可以解决,但是我按这个做法无用,暂时无解。
另一个角度看,由于main函数是定义在libgambit.a中,也没办法把scheme和C混合编程。
Chicken
chicken主包有csi和csc以及一些安装egg的程序,优化力度没有Gambit大,但轻量,同时周边生态非常好。由于和C的交互性比较好,还有chicken-libs和chicken-dev两个附加包,libs只含一个libchicken.so.xx(xx是具体实现版本),运行时加载。当然也支持静态编译,就归属于dev包,里面有.h和.a文件,同时还有个.so的软链接。
Gambit和Chicken都是能把Scheme编译成C源码的实现(另外还有Bigloo)。
Chibi
和前两个相比起来,Chibi只是一个非常小的实现,只有9个文件不到两万行源码,但却很有意思。
9个文件除掉main文件,剩下分为SEXP和EVAL两部分。SEXP包括gc.o sexp.o bignum.o gc_heap.o,S表达求值和两种GC策略及大数。EVAL包括opcodes.o vm.o eval.o simplify.o,实现求值、虚拟机指令、优化。
和最常见的configure/make编译方式不同,Chibi的configure却顽皮地写了句:Autoconf is an evil piece bloatware encouraging cargo-cult programming.,直接用make就可以。即使如此也能做到在很多平台直接编译成功。第一次看到有人这样嘲讽Autoconf,算是说出了我的心声吧。
实现上有很多有趣的实现技巧,比如用GCC的特性,typedef int sint128_t __attribute__((mode(TI)));定义128位int,在Windows平台使用(DBL_MAX*DBL_MAX)和log(-2)定义infinity和nan。
核心形式只有10个:DEFINE,SET,LAMBDA,IF,BEGIN,QUOTE,SYNTAX_QUOTE,DEFINE_SYNTAX,LET_SYNTAX,LETREC_SYNTAX。
chibi支持以C语言写插件并调用(如果不这样,scheme也不可能有大用了),但想从C调用还没找到路径。
S7
对tinyscheme做了极大的丰富,并且持续演进。宏和模块机制借鉴CL。
编译
虽说核心只有.h和.c各一个,但选项很多,又没有提供Makefile,还是要仔细看文档才行。默认把s7.c和repl.c编译成standalone的方式,虽然在安卓上能编译出二进制文件,但运行时要新编译libc的扩展,会遇到诸如没有wordexp.h头文件,没有网络库等。只能加上DWITH_MAIN选项编译s7.c得到standalone文件。还有如果遇到复数函数链接报错,还要在编译时加上DHAVE_COMPLEX_NUMBERS=0手动关闭。
模块
特殊变量*features*能看到当前加载的所有模块列表,但是可笑的是这个列表可以通过provide随意往里添加。虽然正常都是require然后找到那个文件,由该文件的首行实现provide。总觉得这种方式过于老式且似乎不能防止恶意行为。provide行为和lua的module很像,想来当时也是抄的吧,不过lua自己仅使用了一个版本就弃用,是不是也说明了什么。
自带库
大量使用了宏和C语言FFI,复杂不易懂。
back